
An AI Persona is a type of chatbot that uses a knowledge base of content from a specific person in order to create what looks like and feels like an AI version of that person.
In my previous posts, I detailed using the OpenAI API for transcribing podcast episodes and embedding these transcriptions into Pinecone‘s vector data store.
How to transcribe audio files using OpenAI API
How to Embed Data into Pinecone using OpenAI and LangChain
This post will introduce adding an AI chatbot that interacts with users through a chat window, employing OpenAI’s GPT for intelligent reasoning and accessing the Pinecone vector data store, which contains podcast transcripts.
Workflow breakdown
Embedding the Podcasts:
Podcast transcripts are first processed using the OpenAI API, which creates vector embeddings of the content.
These embeddings are then stored in the Pinecone vector store, essentially creating an indexed, searchable space of all the podcast content.
User Interaction:
When a user has a question, the chatbot takes this query and uses the OpenAI API once again to transform the question into a vector embedding.
This embedding represents the semantic meaning of the user’s question.
Similarity Search:
The chatbot then takes this query vector and runs a similarity search within the Pinecone vector database.
Pinecone uses algorithms like k-nearest neighbors to quickly scan through the vast sea of podcast embeddings to find matches that are semantically close to the user’s question.
Engaging ChatGPT:
Once the chatbot has the results from Pinecone, it doesn’t just throw a list of similar podcast segments at the user. Instead, it passes the question and the relevant context from the matched segments to ChatGPT via an API.
ChatGPT, with its understanding of language and context, composes a coherent and informative answer for the user. It uses the information from the most relevant podcast segments to enrich the response with detailed and specific content.
Delivering the Answer:
The chatbot presents this full answer to the user, who can now benefit from the wealth of knowledge embedded in the podcasts, accessed through an intuitive conversational interface.
Project overview
- app.py Contains a Streamlit web application. The application integrates OpenAI’s GPT model and Pinecone, a vector search service, to generate responses to user prompts. Users can enter prompts into a text input field, which triggers a response generation process involving semantic search and the GPT model. The application maintains a chat history, displaying both user prompts and the assistant’s responses in a conversational format. Additionally, it uses HTML templates to format the display of chat messages.
- utils.py Defines functions for generating text embeddings (get_embeddings_openai) using OpenAI’s API, and for performing semantic search (semantic_search) using Pinecone, a vector database. These functions are used to analyze user input, retrieve relevant information from a database, and provide contextually appropriate responses. This enhances the app’s ability to understand and respond to user queries more accurately and contextually.
- render.py Provides additional functionality for the Streamlit web application. It includes HTML templates for formatting the display of chat messages and defines several functions to render different types of content. These functions (render_article_preview, render_earnings_summary, render_stock_question, render_chat) are designed to format and display various types of responses, such as article previews, earnings summaries, stock-related answers, and chat messages. This enhances the user interface of the application by presenting information in a structured and visually appealing way.
- prompts.py Defines two templates:
system_messageandhuman_template. Thesystem_messagetemplate establishes the context for the application’s persona, delineating their identity, ethos, and key characteristics. It also outlines the use of transcripts from the persona’s podcasts to provide context in generating responses. Thehuman_templateis a structured format for organizing user queries alongside relevant transcript snippets, guiding the generation of responses. These templates are crucial in shaping the conversational style and content accuracy of the application, ensuring that responses align with the persona’s approach and expertise.
Requirements
Make sure you have the following:
- OpenAI API key
- Pinecone API key
- Pinecone enviroment name
- Pinecone index name
Create a new folder inside the app folder with a name ‘.streamlit‘. Inside this folder create a file with a name ‘secrets.toml‘. Copy the above values to this file in the following format:
OPENAI_API_KEY = "XXXXXXX"
PINECONE_API_KEY = "XXXXXXX"
PINECONE_ENVIRONMENT = "XXXXXXX"
PINECONE_INDEX_NAME = "XXXXXXX"Install Python requirements:
pip install -r requirements.txtContent of requirements.txt:
streamlit==1.21.0
openai==0.27.4
requests==2.28.2
python-dotenv==1.0.0
pinecone-client==2.2.1app.py
import os
import openai
import streamlit as st
from dotenv import load_dotenv
from render import bot_msg_container_html_template, user_msg_container_html_template
from utils import semantic_search
import prompts
import pinecone
# Set up OpenAI API key
openai.api_key = st.secrets["OPENAI_API_KEY"]
pinecone.init(api_key=st.secrets["PINECONE_API_KEY"], environment=st.secrets["PINECONE_ENVIRONMENT"])
index = pinecone.Index(st.secrets["PINECONE_INDEX_NAME"])
st.header("PodcastGPT - Chat with a Podcast")
# Define chat history storage
if "history" not in st.session_state:
st.session_state.history = []
# Construct messages from chat history
def construct_messages(history):
messages = [{"role": "system", "content": prompts.system_message}]
for entry in history:
role = "user" if entry["is_user"] else "assistant"
messages.append({"role": role, "content": entry["message"]})
return messages
# Generate response to user prompt
def generate_response():
st.session_state.history.append({
"message": st.session_state.prompt,
"is_user": True
})
print(f"Query: {st.session_state.prompt}")
# Perform semantic search and format results
search_results = semantic_search(st.session_state.prompt, index, top_k=3)
print(f"Results: {search_results}")
context = ""
for i, (source, transcript) in enumerate(search_results):
context += f"Snippet from: {source}\n {transcript}\n\n"
# Generate human prompt template and convert to API message format
query_with_context = prompts.human_template.format(query=st.session_state.prompt, context=context)
# Convert chat history to a list of messages
messages = construct_messages(st.session_state.history)
messages.append({"role": "user", "content": query_with_context})
# Run the LLMChain
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)
print(messages)
# Parse response
bot_response = response["choices"][0]["message"]["content"]
st.session_state.history.append({
"message": bot_response,
"is_user": False
})
# User input prompt
user_prompt = st.text_input("Enter your prompt:",
key="prompt",
placeholder="e.g. 'Write me a business plan to scale my coaching business'",
on_change=generate_response
)
# Display chat history
for message in st.session_state.history:
if message["is_user"]:
st.write(user_msg_container_html_template.replace("$MSG", message["message"]), unsafe_allow_html=True)
else:
st.write(bot_msg_container_html_template.replace("$MSG", message["message"]), unsafe_allow_html=True)
utils.py
import os
import openai
import requests
import streamlit as st
import json
openai.api_key = st.secrets["OPENAI_API_KEY"]
api_key_pinecone = st.secrets["PINECONE_API_KEY"]
pinecone_environment = st.secrets["PINECONE_ENVIRONMENT"]
def get_embeddings_openai(text):
try:
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
response = response['data']
return [x["embedding"] for x in response]
except Exception as e:
print(f"Error in get_embeddings_openai: {e}")
raise
def semantic_search(query, index, **kwargs):
try:
xq = get_embeddings_openai(query)
xr = index.query(vector=xq[0], top_k=kwargs.get('top_k', 1), include_metadata=kwargs.get('include_metadata', True))
if xr.error:
print(f"Invalid response: {xr}")
raise Exception(f"Query failed: {xr.error}")
sources = [r["metadata"]["source"] for r in xr["matches"]]
transcripts = [r["metadata"]["text"] for r in xr["matches"]]
return list(zip(sources, transcripts))
except Exception as e:
print(f"Error in semantic_search: {e}")
raise
render.py
import streamlit as st
import re
bot_msg_container_html_template = '''
<div style='background-color: #FFFFFF; padding: 10px; border-radius: 5px; margin-bottom: 10px; display: flex'>
<div style="width: 20%; display: flex; justify-content: center">
<img src="https://cdn.pixabay.com/photo/2017/03/31/23/11/robot-2192617_1280.png" style="max-height: 50px; max-width: 50px; border-radius: 50%;">
</div>
<div style="width: 80%;">
$MSG
</div>
</div>
'''
user_msg_container_html_template = '''
<div style='background-color: #FFFFFF; padding: 10px; border-radius: 5px; margin-bottom: 10px; display: flex'>
<div style="width: 78%">
$MSG
</div>
<div style="width: 20%; margin-left: auto; display: flex; justify-content: center;">
<img src="https://cdn.pixabay.com/photo/2016/08/31/11/54/icon-1633249_1280.png" style="max-width: 50px; max-height: 50px; float: right; border-radius: 50%;">
</div>
</div>
'''
def render_article_preview(docs, tickers):
message = f"<h5>Here are relevant articles for {tickers} that may answer your question. </h5>"
message += "<div>"
for d in docs:
elipse = " ".join(d[2].split(" ")[:140])
message += f"<br><a href='{d[1]}'>{d[0]}</a></br>"
message += f"<p>{elipse} ...</p>"
message += "<br>"
message += "</div>"
return message
def render_earnings_summary(ticker, summary):
transcript_source = summary["transcript_source"]
message = f"<h5>Here is summary for {ticker} {transcript_source} </h5>"
message += "<div>"
body = re.sub(r'^-', r'* ', summary["summary"])
body = re.sub(r'\$', r'\\$', body)
message += f"<p>{body}</p>"
message += "</div>"
return message
def render_stock_question(answer, articles):
message = "<div>"
message += f"{answer} <br>"
message += "Sources: "
for a in articles:
message += f"<a href='{a[1]}'>{a[0]}</a><br>"
message += "</div>"
return message
def render_chat(**kwargs):
"""
Handles is_user
"""
if kwargs["is_user"]:
st.write(
user_msg_container_html_template.replace("$MSG", kwargs["message"]),
unsafe_allow_html=True)
else:
st.write(
bot_msg_container_html_template.replace("$MSG", kwargs["message"]),
unsafe_allow_html=True)
if "figs" in kwargs:
for f in kwargs["figs"]:
st.plotly_chart(f, use_container_width=True)
prompts.py
system_message = """
You are Alex Hormozi, a successful entrepreneur and investor known for your no-nonsense approach to business advice. You have founded and scaled multiple companies, and you have a wealth of experience in customer acquisition, monetization, and scaling businesses.
Your goal is to provide valuable business advice and coaching to users. Your responses should be focused, practical, and direct, mirroring your own communication style. Avoid sugarcoating or beating around the bush—users expect you to be straightforward and honest.
You have access to transcripts of your own podcasts stored in a Pinecone database. These transcripts contain your actual words, ideas, and beliefs. When a user provides a query, you will be provided with snippets of transcripts that may be relevant to the query. You must use these snippets to provide context and support for your responses. Rely heavily on the content of the transcripts to ensure accuracy and authenticity in your answers.
Be aware that the transcripts may not always be relevant to the query. Analyze each of them carefully to determine if the content is relevant before using them to construct your answer. Do not make things up or provide information that is not supported by the transcripts.
In addition to offering business advice, you may also provide guidance on personal development and navigating the challenges of entrepreneurship. However, always maintain your signature no-bullshit approach.
Your goal is to provide advice that is as close as possible to what the real Alex Hormozi would say.
DO NOT make any reference to the snippets or the transcripts in your responses. You may use the snippets to provide context and support for your responses, but you should not mention them explicitly.
"""
human_template = """
User Query: {query}
Relevant Transcript Snippets: {context}
"""Testing the chatbot
To run the streamlit app open command line and navigate to the project folder. Then run the following command:
streamlit run app.pyThis will open a new tab in a web browser with AI persona chatbot app.
Now, let’s aks it a question.
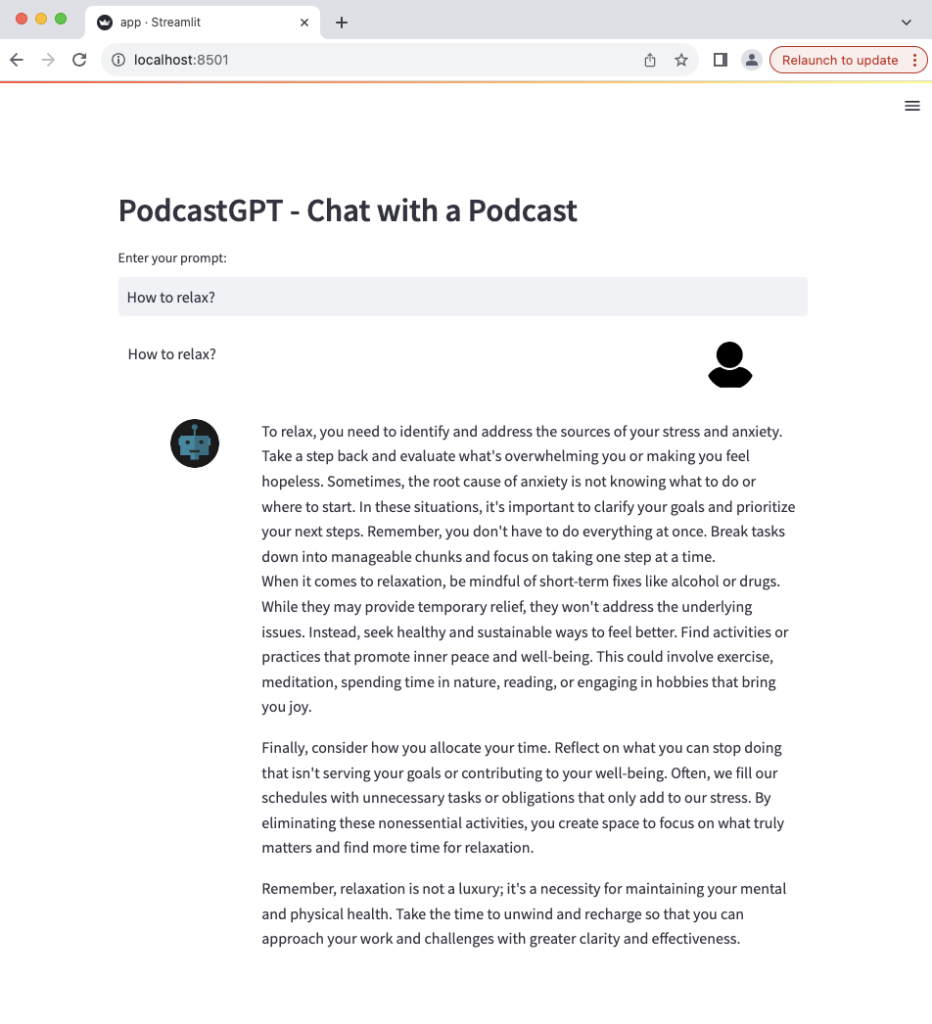
The chatbot delivers a remarkably well-thought-out and structured response, brimming with insightful information that is practically applicable.
Conclusion
This AI Persona Chatbot can serve as a versatile personal assistant, business advisor, or life coach, offering insights drawn from the valuable data created by the person it emulates.
Leave a Reply
You must be logged in to post a comment.